Evaluations
Measure and improve quality through evaluation
Evaluate quality in development and production to identify issues and test improvements.
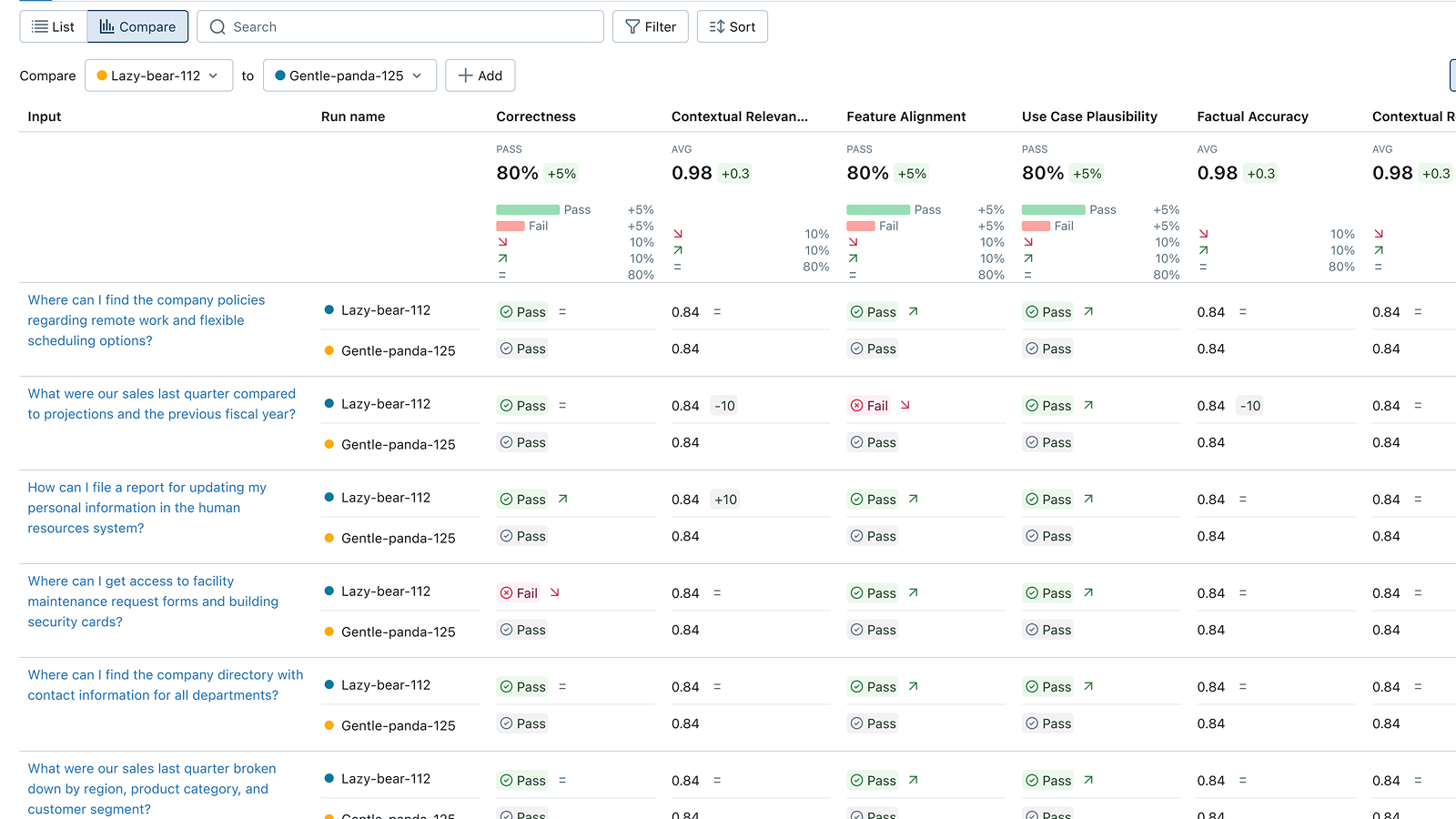
Evaluate free-form language outputs with LLM judges
Pre-built LLM judges
Start with built-in LLM judges for safety, hallucination, retrieval quality, and relevance. Our research-backed judges provide accurate quality evaluation aligned with human expertise.
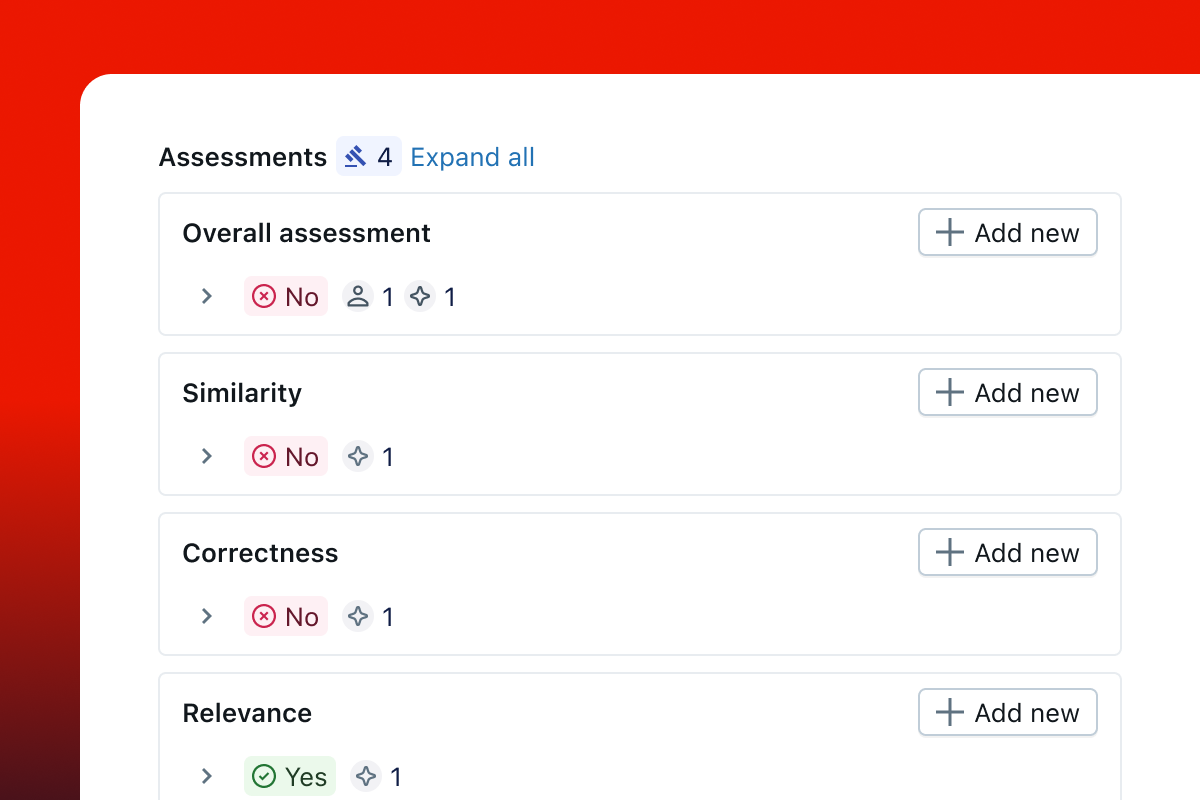
Customized LLM judges
Create custom LLM judges tailored to your business needs, aligned with your human expert judgment.

Use production traffic to improve quality
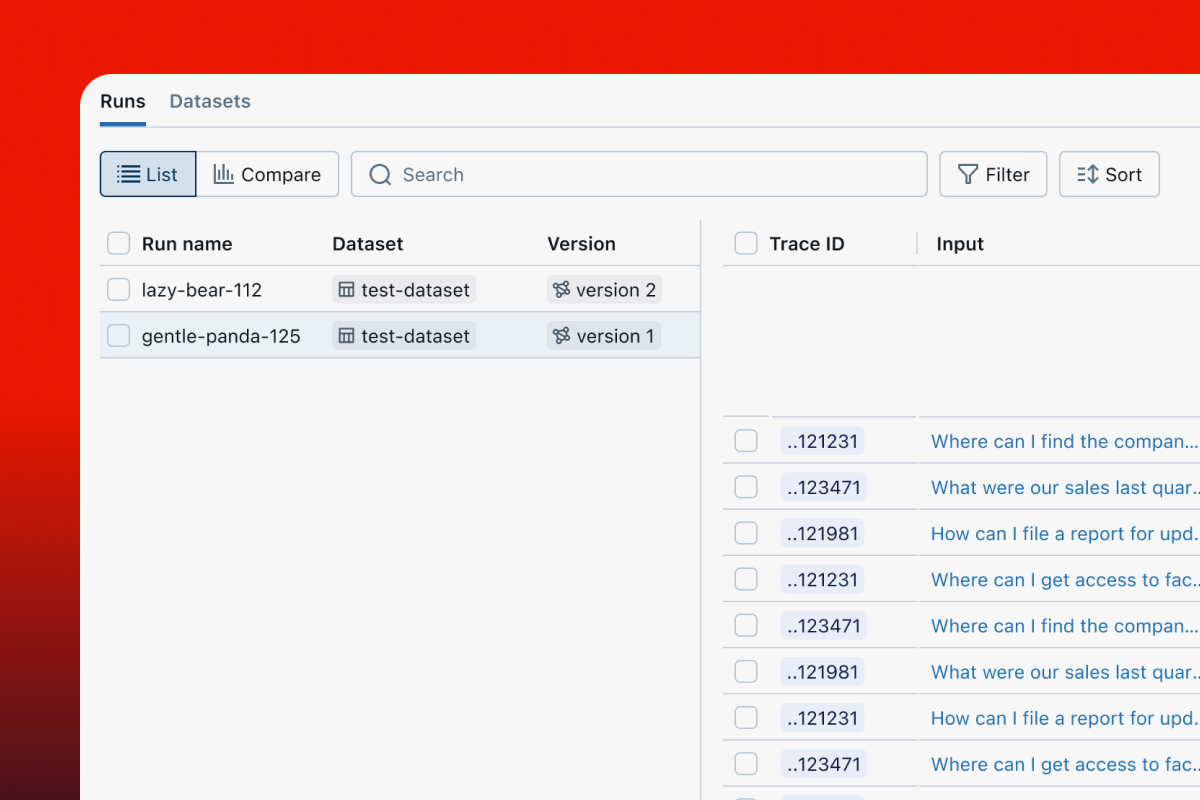
Evaluation datasets
Curate high-scoring traces for regression datasets and low-scoring ones for evaluation datasets to improve quality offline.
Improve quality through iterative evaluation
Test new app and prompt variants
Test application variants (prompts, models, code) against evaluation and regression datasets. Each variant links to its evaluation results, enabling improvement tracking over time.
Customize with code-based metrics
Measure any aspect of your app's quality or performance using custom metrics. Convert any Python function into a metric—from regex to custom logic.

Identify root causes with evaluation UIs
Visualize evaluation summaries and view results record-by-record to identify root causes and improvement opportunities.
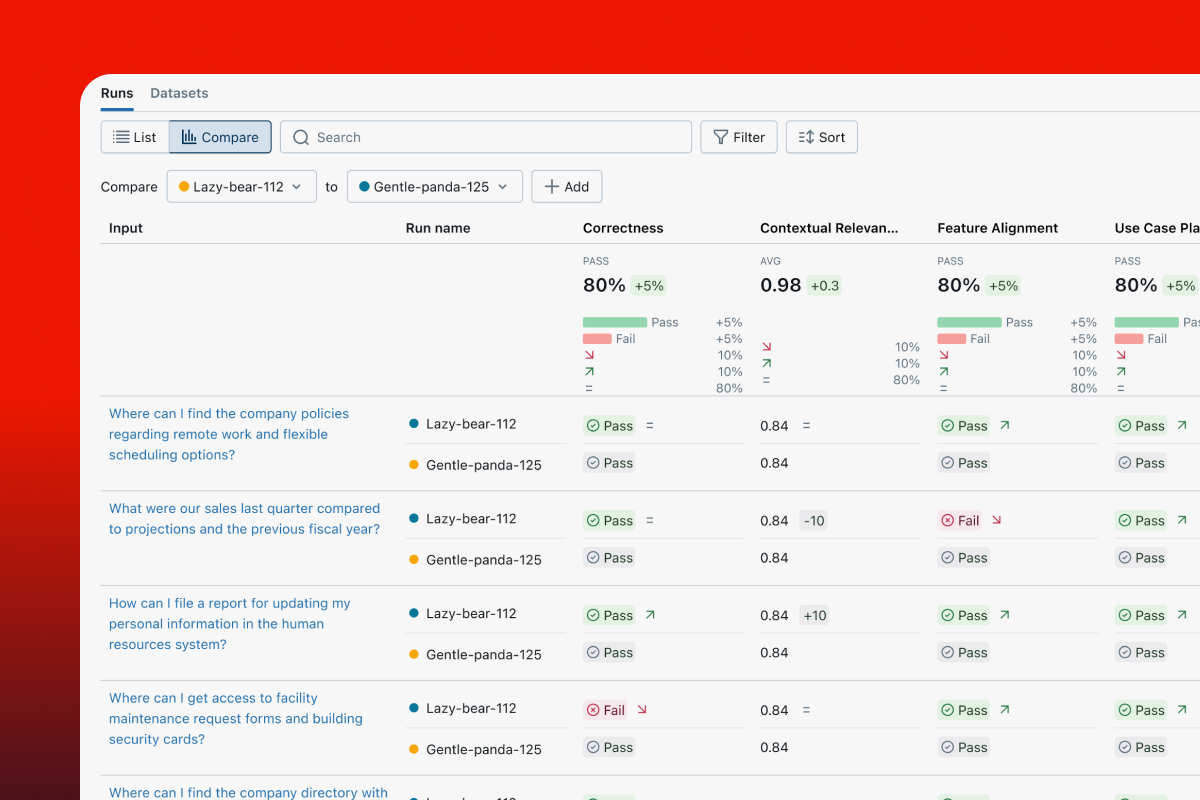
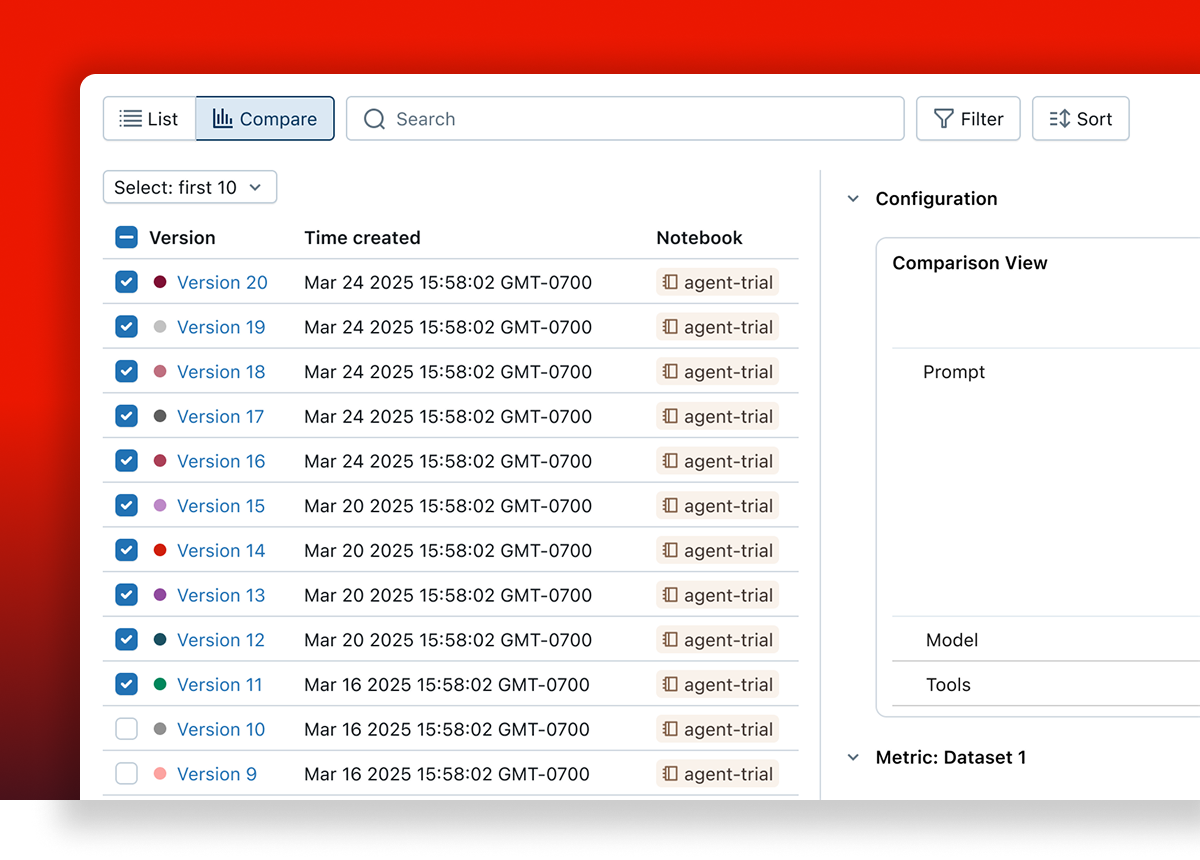
Compare versions side-by-side
Compare evaluations of app variants to understand quality changes. Review individual questions side-by-side in the Trace Comparison UI to debug regressions and inform your next version.
Get started with Managed MLflow
GET INVOLVED
Connect with the open source community
Join millions of MLflow users